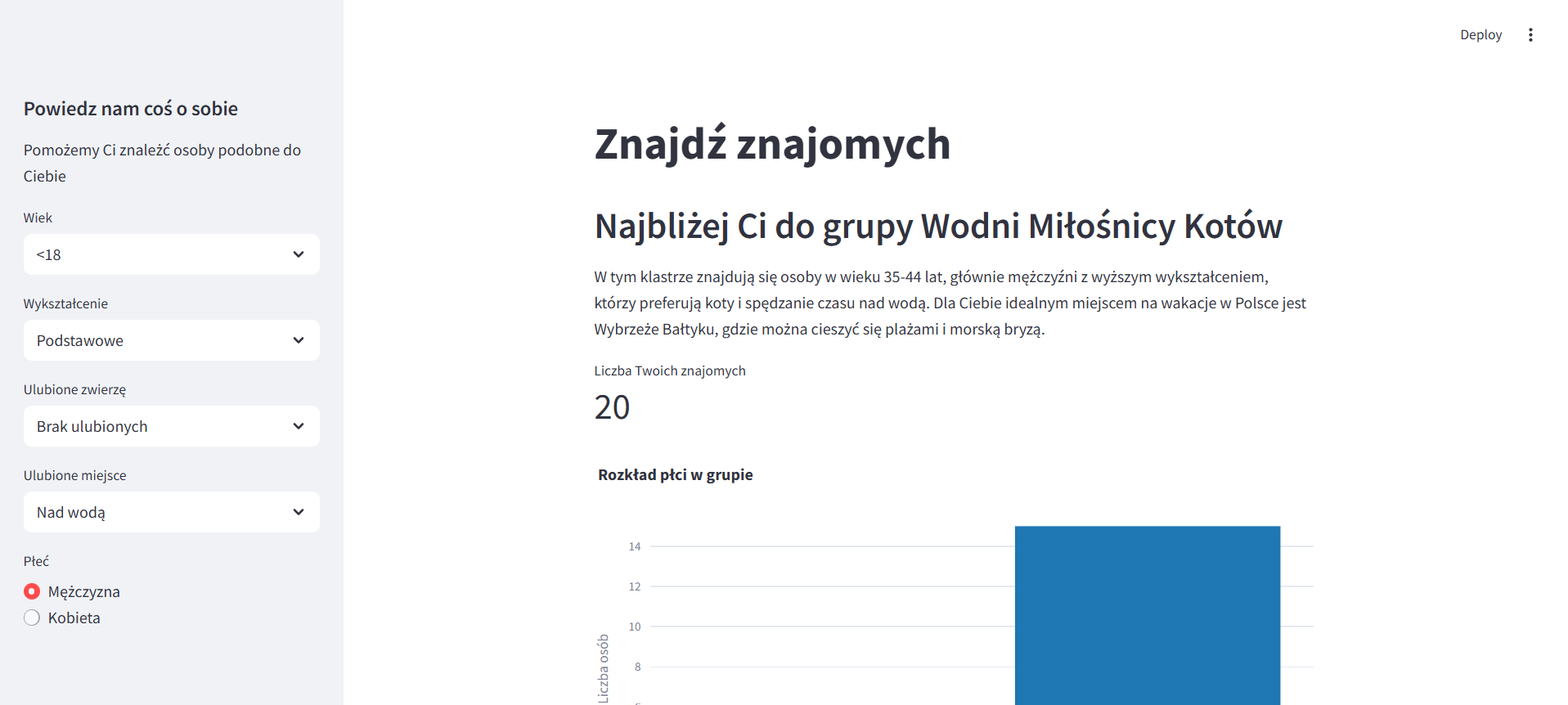
Find friends
Utworzone: 18.04.2025
📌 Opis projektu:
Stworzyłem aplikację opartą na modelu uczenia maszynowego, która analizuje odpowiedzi użytkownika z ankiety i przypisuje go do jednego z wcześniej zdefiniowanych klastrów. Każdy klaster reprezentuje profil użytkownika o określonym zestawie umiejętności, zainteresowań i doświadczenia zawodowego.
⚙️ Funkcjonalności aplikacji:
-
Zbieranie danych: ankieta online z pytaniami m.in. o znajomość technologii, narzędzi analitycznych, doświadczenie zawodowe, zainteresowania AI.
-
Przetwarzanie danych:
- czyszczenie i walidacja danych,
- kodowanie zmiennych kategorycznych (One-Hot / LabelEncoder),
-
standaryzacja cech (StandardScaler / MinMaxScaler).
-
Model uczenia maszynowego:
- klasteryzacja z wykorzystaniem algorytmu KMeans (lub innego, np. DBSCAN / HDBSCAN),
-
analiza silosu cech i metryki dystansu do walidacji modelu.
-
Predykcja:
- użytkownik otrzymuje wynik – przypisanie do klastra,
-
dodatkowo wyświetlana jest interpretacja cech klastra i jego reprezentantów.
-
Wizualizacja wyników:
- dashboard z opisem i cechami poszczególnych klastrów.
Zastosowane technologie:
- Python:
pandas,numpy,scikit-learn,matplotlib,seaborn,streamlit - Uczenie maszynowe: klasteryzacja (
KMeans,silhouette_score,PCA) - Preprocessing:
StandardScaler,OneHotEncoder - Aplikacja interfejsu użytkownika:
Streamlit
Korzyści i zastosowania:
- Pomaga zrozumieć profil użytkownika na podstawie danych wejściowych
- Może służyć jako system rekomendacji kursów, ścieżek kariery lub ról zawodowych
- Pokazuje znajomość pipeline'u ML, od zbierania danych do zastosowania modelu
Tutaj screen z projektu: