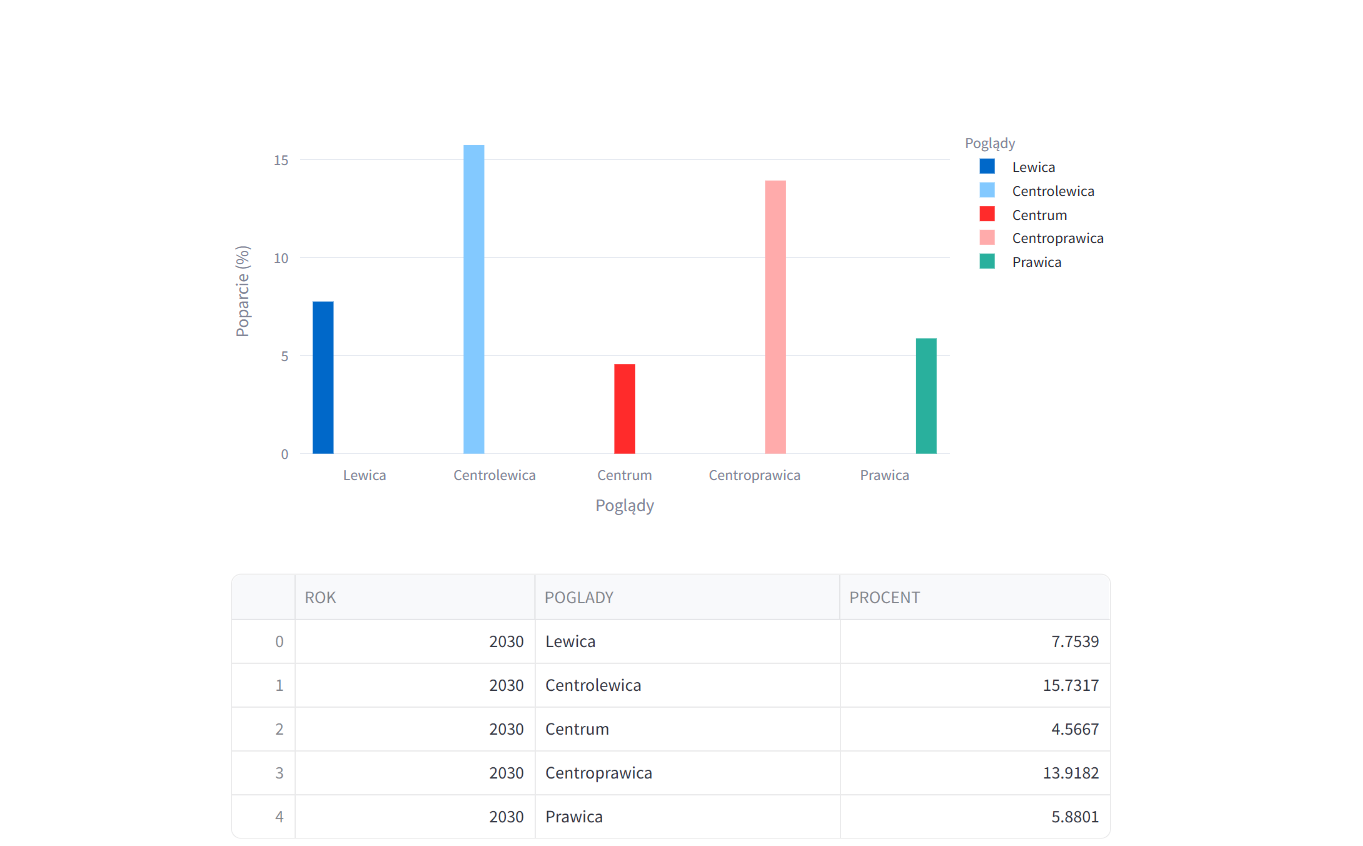
Aplikacja predykcyjna trendów politycznych w Polsce (1990–obecnie)
Utworzone: 03.06.2025
📌 Opis projektu:
Stworzyłem aplikację predykcyjną opartą na danych historycznych z polskich wyborów parlamentarnych, prezydenckich oraz do Parlamentu Europejskiego od 1990 roku. Głównym celem było modelowanie i prognozowanie zmian poparcia społecznego dla różnych poglądów politycznych (lewica, centrolewica, centrum, centroprawica, prawica) w ujęciu czasowym.
Zastosowane techniki:
- Uczenie maszynowe (machine learning):
- Regresja liniowa, modele ensemble (np. Random Forest, XGBoost)
-
Walidacja krzyżowa, tuning hiperparametrów
-
Analiza szeregów czasowych:
- Trendy, sezonowość i dekompozycja czasowa
-
Predykcja zmian poparcia w kolejnych latach
-
Eksploracja danych (EDA):
- Identyfikacja kluczowych korelacji i zależności (np. wpływ typu wyborów, udziału partii, preferencji regionalnych)
Funkcje aplikacji:
- Interaktywne wybieranie roku i typu wyborów
- Dynamiczne prognozy poparcia dla poszczególnych ideologii politycznych
- Wizualizacja trendów i zmian preferencji w czasie
- Możliwość porównywania scenariuszy (np. lata 90. vs współczesność)
Technologie:
- Python (pandas, scikit-learn, matplotlib, seaborn, plotly)
- Streamlit (do stworzenia aplikacji webowej)
- Jupyter Notebook (eksperymenty i prototypowanie modeli)
- Excel (do raportów porównawczych i walidacji danych historycznych)
Wartość analityczna
Projekt pokazuje, jak za pomocą danych historycznych i predykcji można symulować zmiany społecznych nastrojów politycznych i interpretować je w kontekście rzeczywistych wydarzeń. Jest to przykład połączenia analizy danych publicznych, modelowania predykcyjnego i komunikacji wyników w formie aplikacji.
Umiejętności: * ETL i EDA * streamlit * numpy * joblib * sklearn * plotly * pandas * Python * Uczenie maszynowe * Predykcja modelu
Tutaj screen z projektu: